
毕设杂记

毕设标题的灵感
其实没啥灵感可言,导通知说要定个题先应付一下学院的流程,遂上网冲浪寻找合适的题材。因为之后打算继续读研,javaweb相关的课题对我后续套磁的帮助不大,手头上又没有资源跑深度学习,所以打算做一些小体量的机器学习。正好选题那段时间听说outlook套磁容易进垃圾邮箱里,便对 垃圾邮件的识别 产生了一点兴趣(希望不是给自己挖的一个大坑)。所以就在不到一个小时的时间里草率的定下了毕设的课题。
需要了解的知识(持续扩充,缓慢解决)
刚开始我以为这只是一个比较简单的小课题,也就没放在心上,等两语的考试结束以后正式开始的时候,太久没有接触专业知识的陌生感,我才发现我连email是什么,send email的工作具体细节都一无所知,只能硬着头皮干了。
- 什么是电子邮件?电子邮件的生命周期?
- 什么是垃圾邮件?垃圾邮件的生命周期?
- 电子邮件的协议格式有哪些?具体内容是什么?
- 现在主流的垃圾邮件过滤器已经做到了什么程度?不同的模型又有哪些不足之处?现有的改进方法有哪些?
- 数据集选什么样的比较合适?
- 如何衡量一个模型的性能?
个人认为解决了上述的几个问题,会对这个课题有一个较为全面的了解。这个课题并不是非常新颖,在中文期刊中都已经有相当多的研究成果出现,所以有很多的问题可以在 阅读文献 后找到答案。
先搞清楚,电子邮件!
这部分的内容比较杂,我就放一些查到的资料把。一封能在互联网上传播的电子邮件应包含的内容:
根据 RFC 822 和 MIME 标准,一封标准的电子邮件应包括以下几个组成部分:
1. 邮件头部 (Headers)
邮件头部包含了关于邮件本身和邮件通信过程的元信息。常见的邮件头部字段包括:
1.1 发件人 (From)
- 指示邮件的发送者。
- 格式:
From: sender@example.com - 可以包括发件人的姓名,例如:
From: "John Doe" <john.doe@example.com>
1.2 收件人 (To)
- 指定邮件的主要接收者。
- 格式:
To: recipient@example.com - 可以包括多个收件人,用逗号分隔。
1.3 抄送 (CC) 和 密送 (BCC)
- 抄送(CC)表示同时发送给其他人,而密送(BCC)则是发送给其他人但不公开其他收件人的地址。
- 格式:
CC: cc1@example.com, cc2@example.com - 格式:
BCC: bcc@example.com
1.4 主题 (Subject)
- 邮件的主题行,简洁明了地概述邮件内容。
- 格式:
Subject: Meeting agenda for next week
1.5 日期 (Date)
- 指明邮件的发送日期和时间。
- 格式:
Date: Wed, 21 Aug 2024 14:30:00 +0000
1.6 邮件标识 (Message-ID)
- 每封邮件都会有一个唯一的标识符,帮助邮件系统跟踪邮件。
- 格式:
Message-ID: <1234567890@example.com>
1.7 回复到 (Reply-To)
- 用于指定回复邮件时的目标地址,如果与发件人地址不同。
- 格式:
Reply-To: reply@example.com
1.8 其他头部字段
- MIME-Version:标明邮件采用的 MIME 版本,通常是
MIME-Version: 1.0。 - Content-Type:指定邮件内容的类型(如文本、HTML、附件等),在 MIME 邮件中非常重要。
- Content-Transfer-Encoding:描述邮件内容的编码方式(如 Base64 或 Quoted-Printable)。
2. 邮件正文 (Body)
邮件的正文是邮件的核心部分,包含具体的交流内容。正文的格式会根据 Content-Type 头部字段进行不同的处理。
2.1 MIME 邮件的编码
- 如果邮件包含非 ASCII 字符或附件,它将使用 MIME(Multipurpose Internet Mail Extensions)标准进行编码,常见的编码方式有:
- Base64:用于编码二进制数据(如图像、文档等附件)。
- Quoted-Printable:用于编码较为简单的文本数据,避免控制字符导致邮件乱码。
2.2 文本邮件 (Text)
- 纯文本(text/plain)邮件的正文内容通常是不带格式的文本。
- 格式:
Content-Type: text/plain; charset="UTF-8"
2.3 HTML 邮件 (HTML)
- HTML 格式(text/html)邮件允许在正文中嵌入格式化文本、链接、图像等内容。
- 格式:
Content-Type: text/html; charset="UTF-8"
2.4 多部分邮件 (Multipart)
- 如果邮件包含多个部分(例如,文本和附件),则会使用 multipart 类型的内容格式。
- 格式:
Content-Type: multipart/mixed; boundary="boundary_string"
3. 附件 (Attachments)
- 邮件可以包含附件文件,附件将通过 MIME 编码方式嵌入到邮件正文中。
- 每个附件都会有一个独立的内容描述,如
Content-Type和Content-Disposition。 - 示例:由上述的种种可以看出,email的头中蕴含这丰富的信息可以用于判断邮件是否为spam,但是它和邮件体带来的信息又是不同的。
1
2
3Content-Type: application/pdf; name="file.pdf"
Content-Disposition: attachment; filename="file.pdf"
Content-Transfer-Encoding: base64
什么是垃圾邮件?
根据中国互联网协会发布的《反垃圾邮件规范》中对垃圾邮件的界定:
- 收件人事先没有提出要求或者同意接收的广告、电子刊物、各种形式的宣传品等宣传性的电子邮件;
- 收件人无法拒收的电子邮件;
- 隐藏发件人身份、地址、标题等信息的电子邮件;
- 含有虚假的信息源、发件人、路由等信息的电子邮件。
垃圾邮件又通常具备以下特征:
- 以商业传播或恶意手段的传播。
- 使用不真实的发件人地址。
- 匿名或不明来源。
- 附有可疑的链接或附件。
- 有较多的语法错误、拼写错误以及格式不规范等问题。
垃圾邮件的定义并非绝对,常是因人而异的。一封邮件对于用户A而言是垃圾邮件,对于用户B而言不一定是垃圾邮件。因此在设计垃圾邮件过滤系统时,需要学习不同用户的需求差异。也即该系统需要具备用户性。
电子邮件的传输协议
电子邮件的发展已经经过了较长的时间,这其中演变制定出了很多高效可行的网络传输协议,包括:
SMTP(Simple Mail Transfer Protocol)
- SMTP 是用于电子邮件发送的协议,负责将电子邮件从发件人邮箱传输到收件人邮箱的邮件服务器。SMTP 主要用于邮件的发送和转发,而不负责存储邮件。
POP3(Post Office Protocol 3)
- POP3 是用于从邮件服务器接收电子邮件的协议。它允许用户下载邮件并将邮件存储在本地计算机上。POP3 的工作方式是将邮件从服务器下载后,通常会删除服务器上的邮件副本。
IMAP(Internet Message Access Protocol)
- IMAP 也是一种接收邮件的协议,但与 POP3 不同,IMAP 允许邮件保留在服务器上,并且支持多设备间同步。用户可以从任何设备上访问邮件,并查看邮件的实时状态(如已读、未读、标记等)
MIME(Multipurpose Internet Mail Extensions)
- MIME 是扩展电子邮件功能的协议,允许电子邮件发送多种类型的内容,如文本、图片、音频、视频等。MIME 是 SMTP 的一种补充,定义了如何编码多种类型的内容,以便通过电子邮件传输。
ESMTP(Enhanced SMTP)
- ESMTP 是对 SMTP 协议的扩展,增加了更多的功能和特性,如身份验证(SMTP AUTH)和加密等。它向SMTP协议添加了一些可选功能,以支持现代的电子邮件服务。
DSN(Delivery Status Notification)
- DSN 是一种标准机制,用于告知发件人邮件的传送状态,包括成功、延迟或失败等。它是 SMTP 协议的一部分,用于邮件传递过程中状态反馈。
当前主流的垃圾邮件过滤方法
就技术层面而言,当前的垃圾邮件过滤方法主要分为三大类:
- 基于IP的过滤。
- 黑白名单
- 服务器端控制
- 安全认证机制
- 基于内容的过滤
- 基于规则的方法:
- Ripper、决策树、Booting决策树、粗糙集
- 基于统计的方法:
- Bayes、KNN、SVM、Winnow
- 基于规则的方法:
- 基于行为/SMTP协议的过滤
这些方法各有优势和局限性。基于规则的内容过滤方法虽然需要专家精心制定规则,准确性较高,易于理解,但维护成本较高,且规则的公开性使得垃圾邮件发送者能够学习并规避这些规则。而基于统计学习的方法虽然生成的规则难以直观理解,但能够在一定程度上规避上述问题,因为它们是通过大量数据学习得到的“隐式规则”。
数据集的选择
1. trec2006c
- 中文邮件集,每一封邮件都由完整的邮件头和邮件体构成。
2.
初步实现
如果只是单纯的实现一个基于NBC的垃圾邮件分类器的话其实是一个很简单的课题,在不考虑性能、内存的情况下,用一个极小的数据集训练的分类器加上python已经很好的集成了常见的机器学习的模型,通常数十行代码就可以搞定。接下来的代码就是一个简单的例子。
代码详见 en_train.py,以下是训练的结果:
1 | Outcome: |
需要注意这里的数据集并非中文垃圾邮件数据集,而是一个简化的英文邮件数据集,并且只保留了邮件的正文部分。阅读文献我们会发现一封能在互联网上流通的邮件通常有:收件人(To)、抄送(CC)、密送(BCC)、主题(Subject)、正文(Body)、签名(Signature)、附件(Attachment)等数个部分构成。这显然是不合理的,但是作为一个初代分类器,这样就已经非常nice了!接下来的任务就是在这基础上慢慢地做大、做强~さあ、行くぞ!
改用更大的数据集!
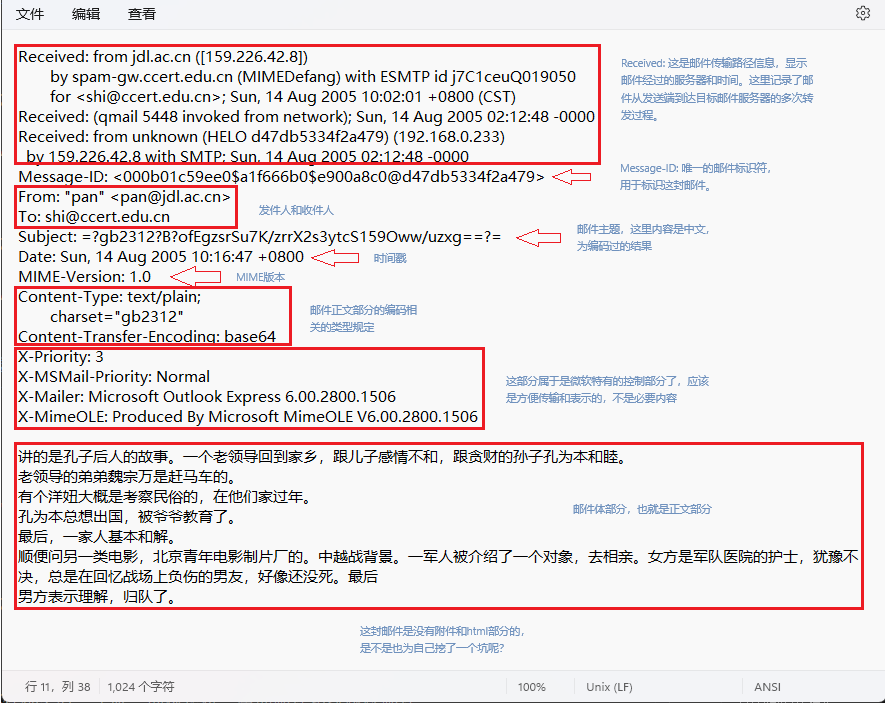
上述的始め数据集只有正负例各25个,接下来来个大的trec06c( https://plg.uwaterloo.ca/~gvcormac/treccorpus06/ )。该数据集一共64,620 个文件,216 个文件夹,其中正样本数21766个,负样本数42454个。而且这个数据集是一个由不带附件的原始邮件组成数据集。邮件头和邮件体有时采用了不同的编码方式,所以需要对邮件头和邮件体进行解码。比如下面列出的一封邮件:
1 | Received: from jdl.ac.cn ([159.226.42.8]) |
信息量非常大,在网上可以看到一些博主在训练模型时,直接将邮件头全部砍掉,只保留邮件体部分,将这个完整的数据集简化为同上的mini数据集。这怎么看都是不对的!哪怕它们跑出来的结果再好。我们要做的过滤器应该是同时考虑邮件头和邮件体两部分的内容的逻辑上完整的过滤器。这一部分的参考了这篇,所以在训练之前,需要搞清楚一封正常的电子邮件是由哪几部分构成的。
- Title: 毕设杂记
- Author: tasukyou
- Created at : 2024-11-29 21:15:40
- Updated at : 2024-12-29 17:08:01
- Link: https://github.com/tatsu-kyou/2024/11/29/毕设杂记/
- License: This work is licensed under CC BY-NC-SA 4.0.