
Graduation Project--Papers Reading

前言杂谈
读的论文越多才发现自己对课题理解越浅薄,很多问题点没有搞清楚就开始着手实现细节,慢慢地埋下了许多祸根。不过目前读到的论文也普遍存在一个共同的问题——没有开源,实验就都是不可复制的,对实验精度还是普遍存疑的。本着开源精神,毕设的所有代码都将以开源为前提进行编写,尽量做到可轻松复现,结果真实。
OK,闲话少叙,开始吧!
1. 基于规则的垃圾邮件过滤比较研究
作者:汤、孙
文章篇幅极短,简要介绍了Ripper算法、C4.5决策树和AdaBoost算法的基本原理后,给出了这三种基于规则的垃圾邮件过滤方法的实验比较结果。结论是AdaBoost算法的效果最好,但实验也发现它的计算复杂度较高,耗时更长。
由于篇幅极短论文基本上没有对任何细节和知识点做更详细的介绍,我认为对我的课题有帮助的地方有一下几点:
- 简要介绍了基于规则的垃圾邮件过滤的流程。

- 提到了特征选择后应该做特征提取来降维。
- AdaBoost算法在众多基于规则的过滤算法中效果最好,但实验也发现它的计算复杂度较高,耗时更长。
2. 基于多过滤器集成学习的在线垃圾邮件过滤
作者:刘、王
时间:2008
文章详略得当,提出了多学习器集成学习的过滤模型,并通过实验证明了集成学习的模型精度优于单一模型。但是继续阅读文献会发现集成学习的模型精度并不总是能优于单个模型中的最佳模型,需要选择合适的学个体学习器进行集成才能达到较为理想的效果。
由于论文并没有做集成模型和个体学习器的对比实验,所以我认为对我的课题有帮助的地方有一下几点:
- 较为准确的阐述了邮件过滤系统的特性:在线性、结构性、客户性和非均匀性(当然也不是官方描述,可以做调整)。
- 集成学习在垃圾邮件过滤上的应用。
- 验证集成学习的效果时需要加上比较实验。
3. 基于规则的垃圾邮件过滤系统设计与实现
作者:郑
硕士论文,对于理论基础介绍的相当详尽。主要基于已有的中文垃圾邮件过滤规则集Chinese_rules.cf进行优化改进,利用神经网络训练模型,实现了一个基于规则的垃圾邮件过滤系统。遗憾的是,该文章年代久远,论文中使用的规则集已停止维护(见下图),最后一代能否适应当下垃圾邮件的复制环境还有待实验验证。
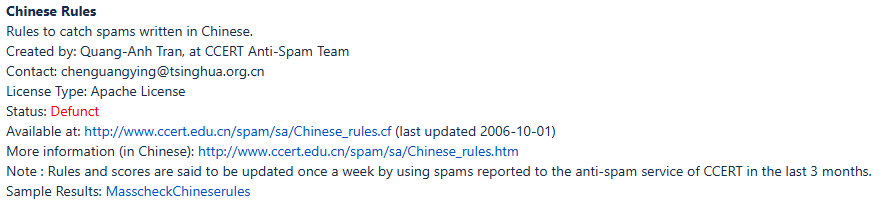
整体看来,该论文仍有值得学习的地方:
- 只要有可持续更新的规则集,仍可利用基于规则的方法进行垃圾邮件过滤。
- 规则集不应过于复杂,否则会严重拖垮计算性能。
- 规则集能否机器生成,或将解决规则集维护成本较大的问题。
4. 加权贝叶斯邮件过滤方法研究
作者:张
硕士论文的传统,背景信息和基础知识较为详尽。文章介绍的模型对NBC进行了改进,分别对邮件头和邮件做了特征提取(职位特征向量),并按一定分权值进行加权整合,得到一个加权分数来判断是否为垃圾邮件。
可能存在的问题和值得学习的亮点:
- 加权思想。
- 为什么要对邮件头做与邮件体相似的特征提取?
- 将每一条原始样本转换为若干个指纹向量的特征提取方法。
5. 结合规则过滤和内容过滤的综合型反垃圾邮件系统的研究与实现
作者:张
时间:2009
硕士论文,关于电子邮件的生命周期的解释十分详细,对后续撰写论文有较大的帮助。可能因为年代久远,对“现有技术”的分类与其他论文存在出入,不过这一个块内容仁者见仁,理清楚就行。
- Title: Graduation Project--Papers Reading
- Author: tasukyou
- Created at : 2024-12-25 22:52:06
- Updated at : 2025-01-05 16:50:33
- Link: https://github.com/tatsu-kyou/2024/12/25/Papers-Reading-of-Graduation-Project/
- License: This work is licensed under CC BY-NC-SA 4.0.